
Interoperable Component Patterns
Wow! This takes me back! Please check the date this post was authored, as it may no longer be relevant in a modern context.
At EmberConf this year I was privileged to be in front of a few hundred web developers to talk about interoperable components (video of the talk here). My curiosity about how to best write a UI component usable across many environments started nearly 18 months ago. At that time HTMLBars, a refactor of Ember’s template system to be more HTML-aware, was just landing in applications. We were considering what invoking a W3C Custom Element might look like in Ember, and trying to reason about how information could be passed in and out.
W3C Web Components have been described several times as a “loose collection of specifications”. The best practices for authoring standards-based web components, or for writing a framework that can consume them, are emergent at best. The draft specifications tread lightly on the ground of what should be idiomatic.
Despite the vagueness of the standards-guided process (which is less far along and less stable than many presume), there are three guiding patterns you can follow to write an interoperable component usable across a variety of settings.
Let’s take a look.
Patterns
The word “pattern” in software has its origins in architecture.

The usage is coined by Christopher Alexander and his collaborators in A Pattern Language, a 1977 book on building and urban design. The work is predicated on the idea that people exposed to an environment, let us say the “users”, can know more about the successes and failings of a solution than the designer. Thus to learn we should look to how people use things, and less at what the designs were intended to do.
Patterns are:
- User-centric
- Designed, but based on experience
- Patterns are not a guide to implementation
Importantly, a pattern is a tool for discussion. It is not a guide for implementation with practical steps, or indeed with any single realization. We should remember that just because a building or program adheres to a pattern it does not make it a good in all aspects. It may remain unsafe, or have significant faults elsewhere.
Sometimes as programmers, especially experienced ones, it is tempting to wave away a class of problems, real problems, with the advice “you must be using the wrong pattern”. That isn’t enough. Identifying a good pattern is the beginning of a development process, not the end.
Interoperability

What do we mean by interoperability? On the web, there are a couple different ways a component could be invoked. We’re going to talk about components that could be invoked in these two scenarios:
- Rails server builds an HTML string, browser parses the HTML string, component boots in the browser
- React template builds some DOM, component boots in the browser, component is implemented with Vue.js
In other words a component usable from any client-side and in-browser consumer, or usable in HTML returned over HTTP to a browser. Many modern JavaScript tools provide some form of server-side rendering for their components, and we are not going to address that use-case.
And just like we must consider multiple occurrences of a patterns use to identify it in buildings…

(these are three examples of “Sheltering Roof” from A Pattern Language) we must also pick a number of consuming environments to evaluate the interoperability of a component. For this post we will consider these consumers.

Each of these possible invocation environments has a different implementation and syntax for calling an interoperable component.
I’m going to share three patterns you should follow to author an interoperable component, one that can be called across many environments. This advice is practical, and though I’m making these suggestions in 2016 I’m also optimistic that these patterns represent a stable platform to author maintainable solutions.
Pattern #1: Custom Elements

Custom Elements are a draft spec being authored by the W3C. It is part of the family of specifications that are normally called W3C Web Components. The development of these specifications has been underway for about five years, with a strong push by Google.
Custom Elements allow us to invoke JavaScript-defined behavior when an element is used, both via DOM APIs and HTML parsing. Let’s see what that looks like:

The DOM API can be called imperative. It describes the implementation of a solution, in this case creating a node that could be attached to the DOM tree of a document. HTML can be called declarative, in that it describes what to do (make a tag), but not the implementation. Often, you can think of declarative HTML as something the HTML5 specification tells browsers how to execute as imperative DOM code.
Custom Elements require a - in their name. Mostly this is an assurance
from the specification that new tags with - will not be added to HTML.
A custom element will not conflict with a future specified element.
Because their invocation is the same as any specified element, custom elements integrate nicely into HTML and into library and template engines. By being built on the DOM (or less often today, HTML), these engines already support Custom Element invocation.
For example, here is how a custom element can be called across a number of environments:

This just works. Great.
However this patterns is “Use Custom Elements via a polyfill”. Why use a polyfill? Well here is an example of how to register a custom element, how to set it up so it can be invoked:

This API for Custom Element registration is supported in all browsers named “Chrome”.

Or in browsers based on Chrome. A polyfill is needed to support other browsers such as Edge, Firefox, and Safari.
But wait!
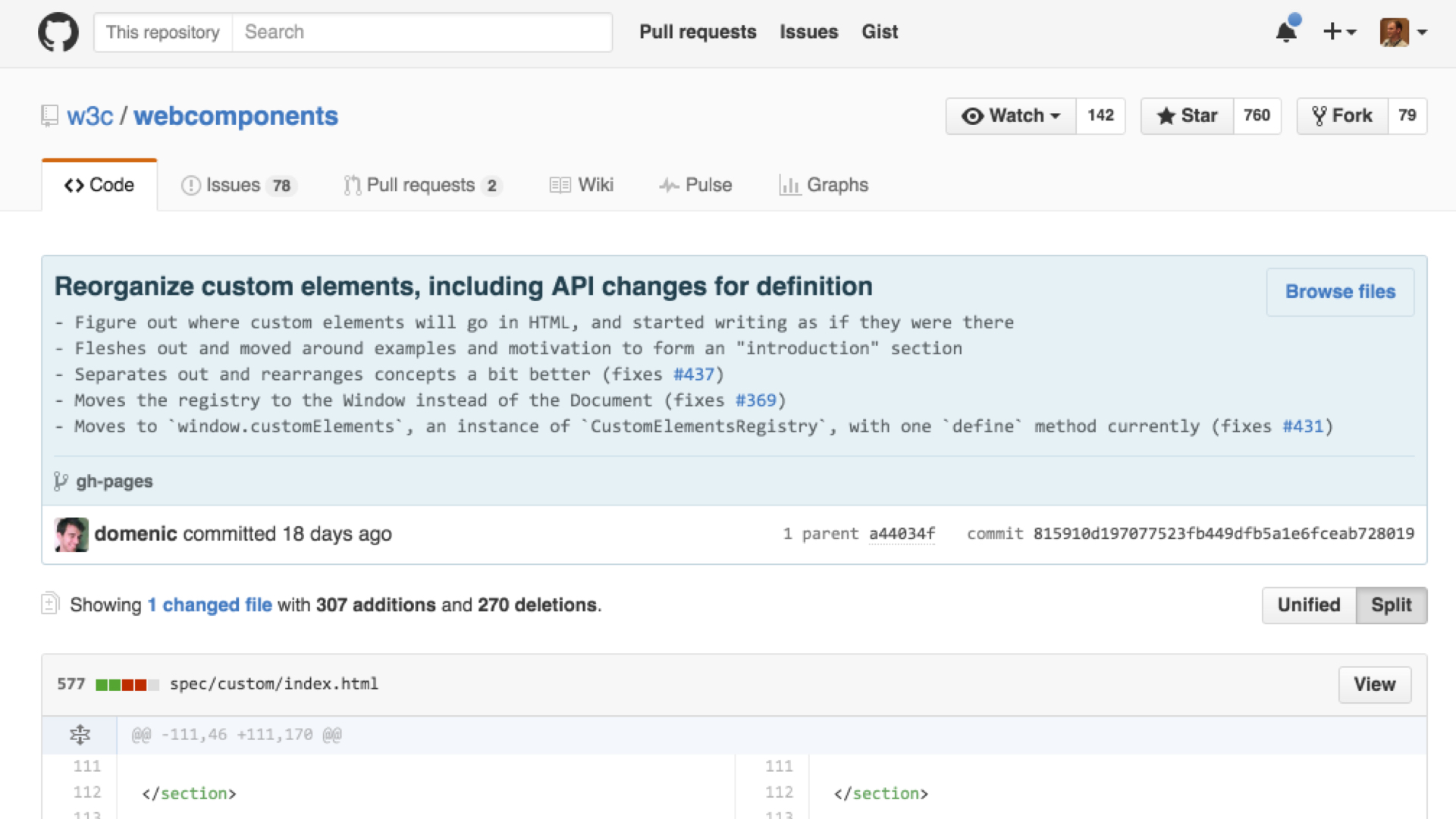
It turns out this API is still a draft specification, and as such is still liable to change. In fact despite being underway for nearly five years, some browser vendors have only recently begun contributing to the web component standards process. Consequently the drafts are still quite unstable. This applies to other parts of W3C Web Components as well, such as Shadow DOM which just landed a major rethink.
The spec’d API for registering a custom element was changed in March 2016:
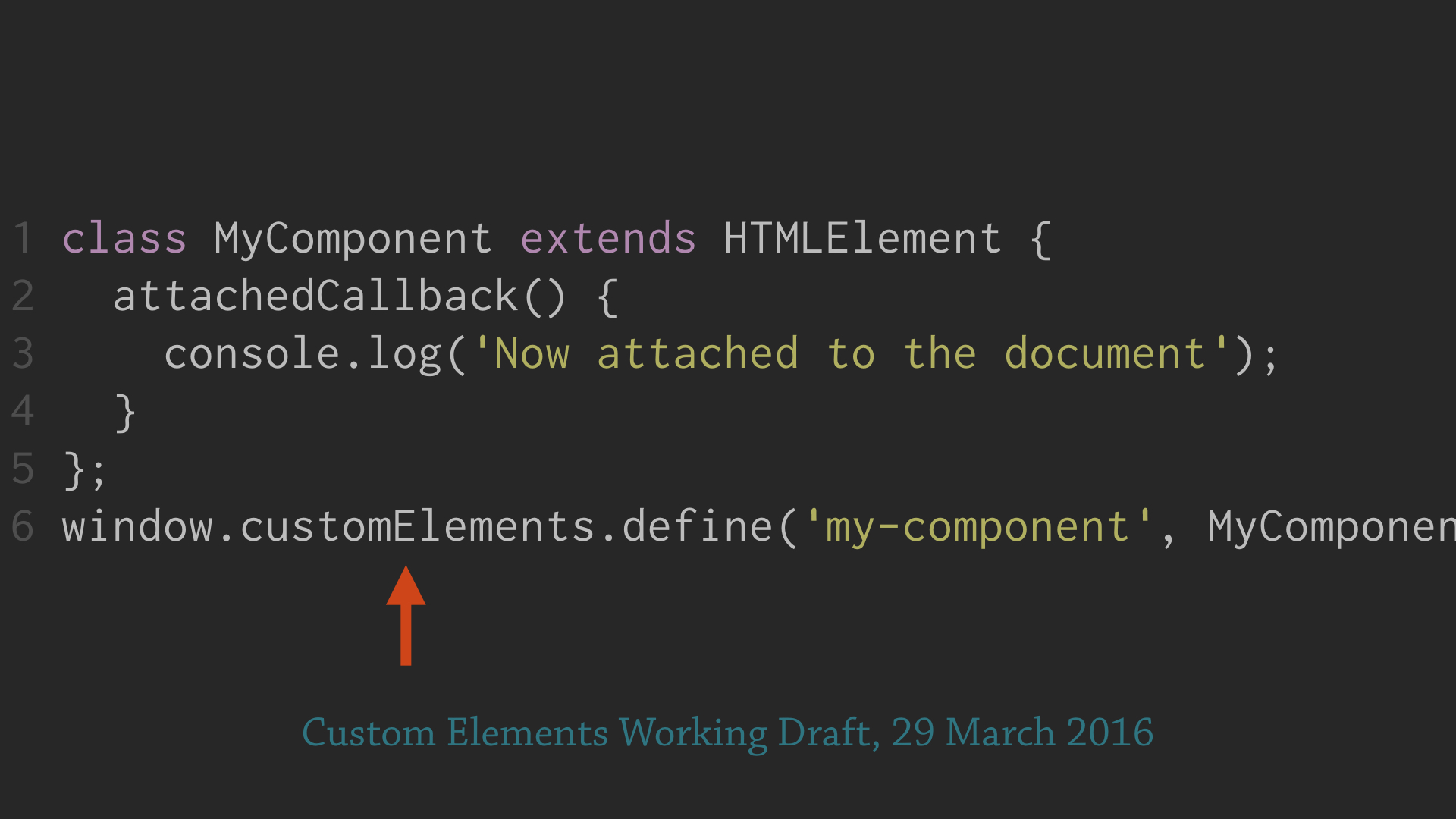
Thus not even browsers named “Chrome” support the Custom Element draft specification, not in early 2016. This is the real motivation for suggesting a polyfill: The Custom Element specification is too unstable to attempt using directly even where there is browser support. Instead rely on a polyfill to isolate your app code from the churn of the standards design process.
There are three ways to author a custom element I suggest considering:
- X-Tag is a Microsoft-authored polyfill and wrapper for Custom Elements. The API for X-Tag is completely different than anything suggested in the specification, and because of this I expect it is the most stable option.
- A Google maintained polyfill is also quite minimal, however couples your code closer to the shifting draft specification.
- Polymer is a custom element authoring solution built on the Google polyfill. Polymer attempts to demonstrate not only what web components can do, but also attempts to design what the future of custom element authoring might be. It blurs the line between polyfill and prototype, and this can make it difficult to know what features are reliable foundations for your library or application.
Custom Elements provide a portable foundation for an interoperable component, and there are great authoring libraries out there that can isolate your code from API churn. Using them in production today is quite possible.
Pattern #2: Attributes
With an invocation method chosen, lets consider how to get data in to a component.

Why attributes? To demonstrate why, we will take a small digression into the HTML spec. Like any of these three patterns, there are always two perspectives to consider: That of the component author, and that of the component consumer. First, we’re going to look at the problem of how to pass data to a component from the perspective of a component author.
Earlier in this post, HTML was described as declarative and the DOM as imperative. A common facet of declarative APIs is that they exercise a lot of restraint, and that the same functionality may be available in an in imperative form.
HTML can define attributes for an element, and attributes may be reflected
as a property on the DOM node. In this example, the attribute id reflects to
a property with the same name:
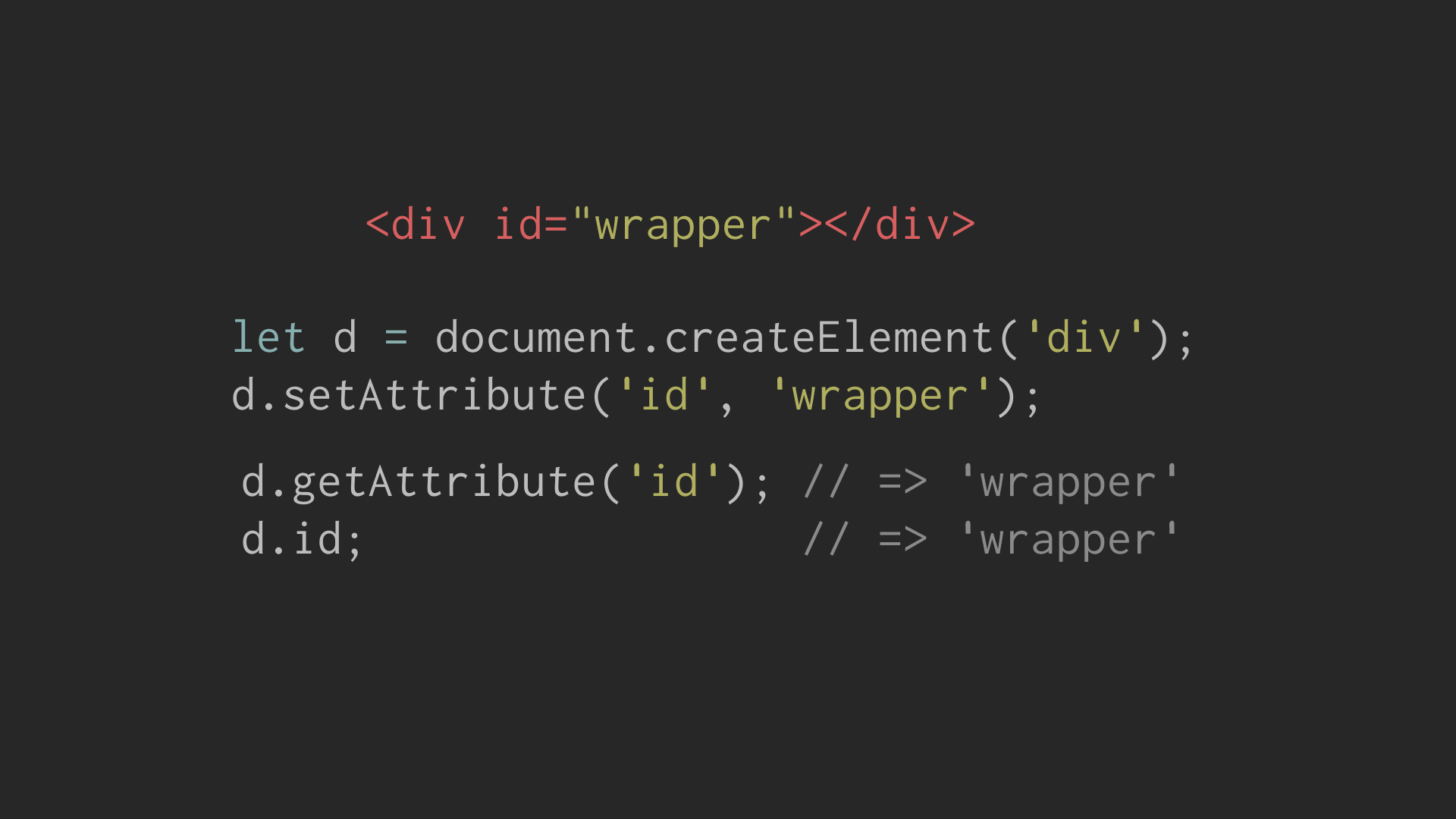
However this isn’t always the case. If an unknown attribute, such as wrapper-id
is specified it is assigned as an attribute but will not reflect to a
property. For example:
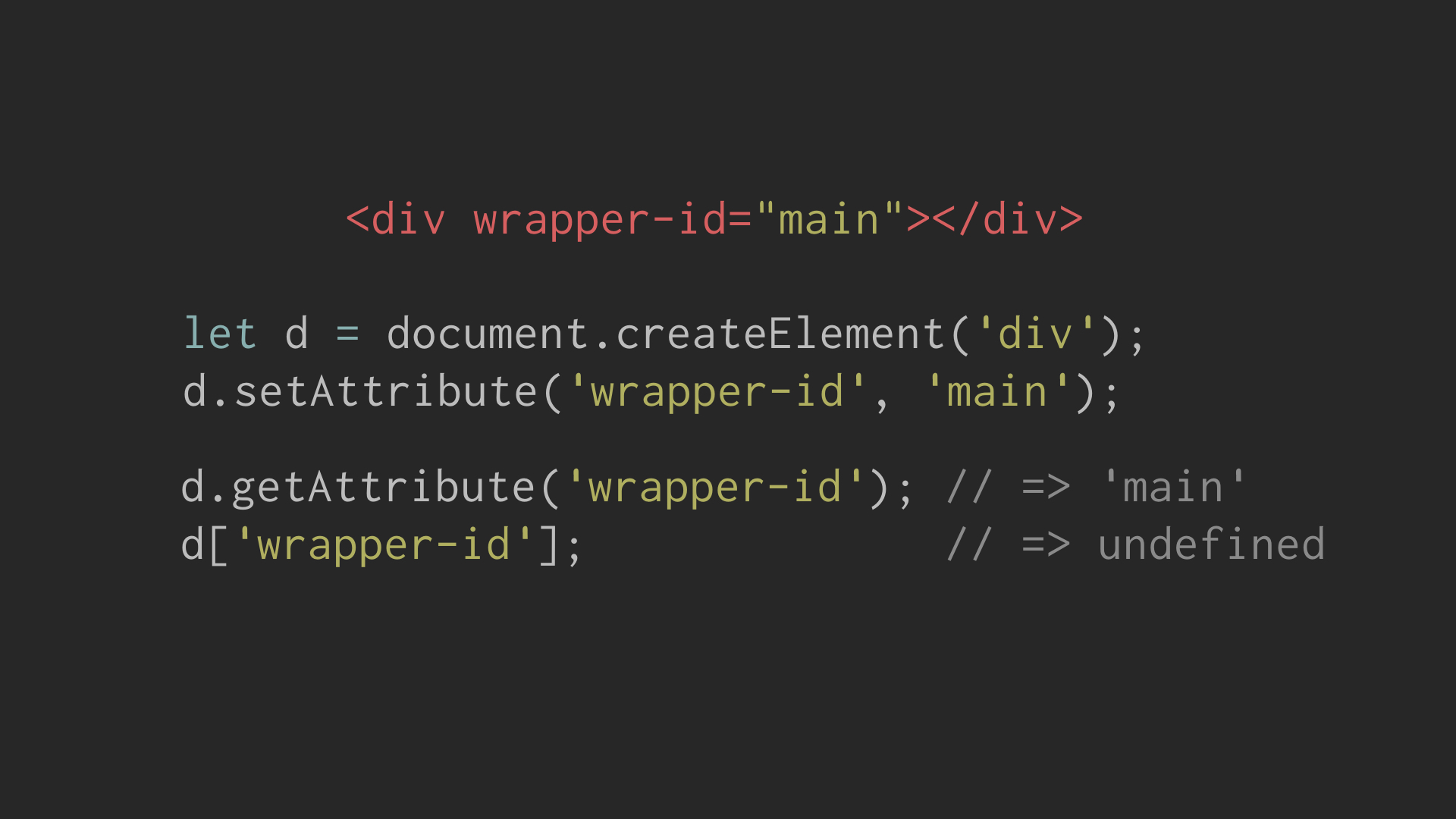
For some attributes the reflected property may take on a different value
than the attribute. For example the boolean attribute hidden:
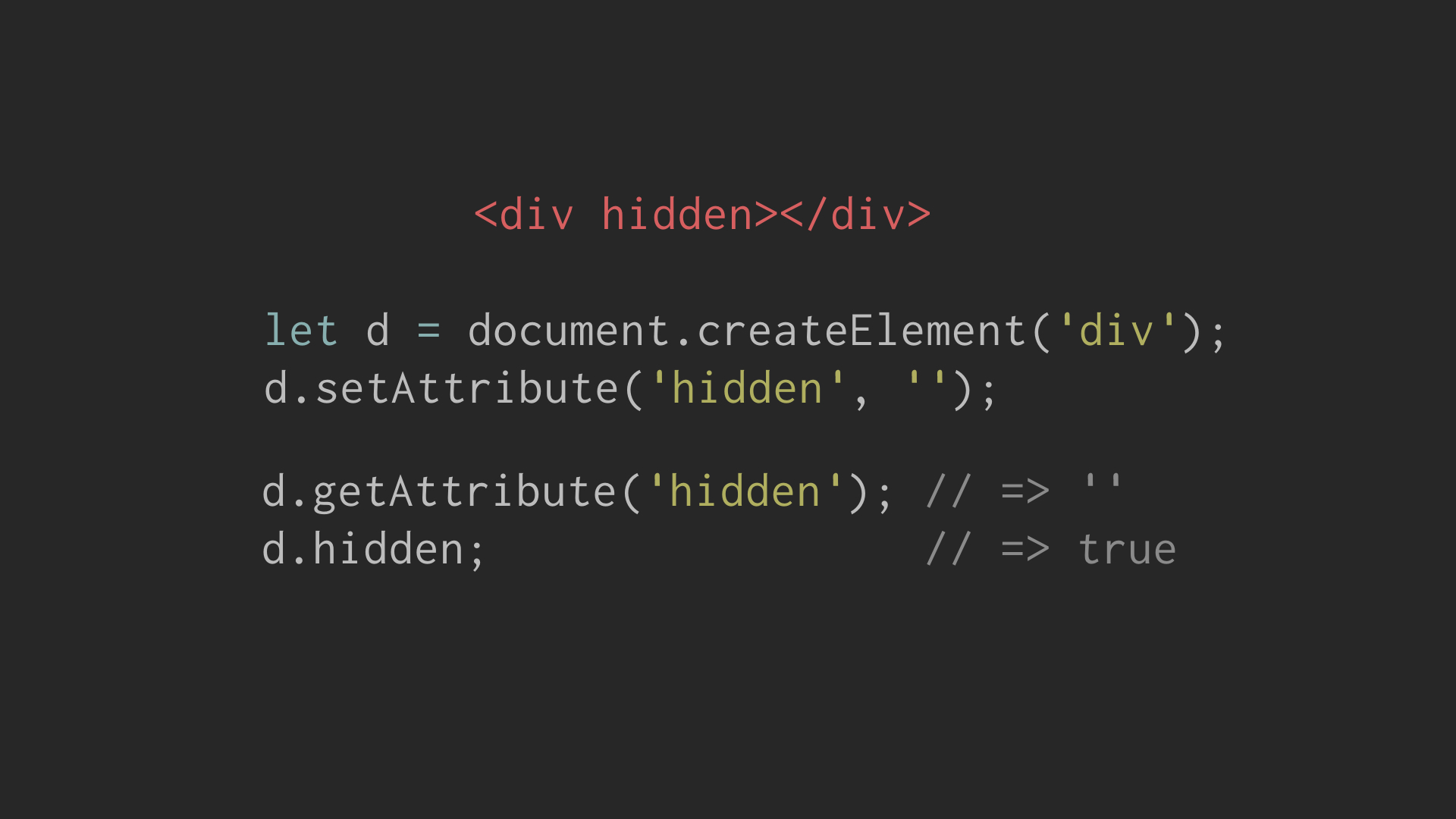
There are weirder examples as well, but lets do some spec spelunking and
see why hidden behaves like it does. The hidden attribute section of the
HTML5 spec is a good place to begin:

So what is a “boolean attribute”.

This section explains the logic for when an attribute is true or false, however
it does not explicitly mention the value of the DOM property hidden.
The bottom of the hidden attribute section has a clause we can see often
in the HTML5 spec:

The “IDL attribute must reflect the content attribute”. IDL, or Interface
Definition Language, is a DSL that describes the interface for a DOM node. Looking
at the IDL for div (which was the tag we used hidden with) is the next
stop:
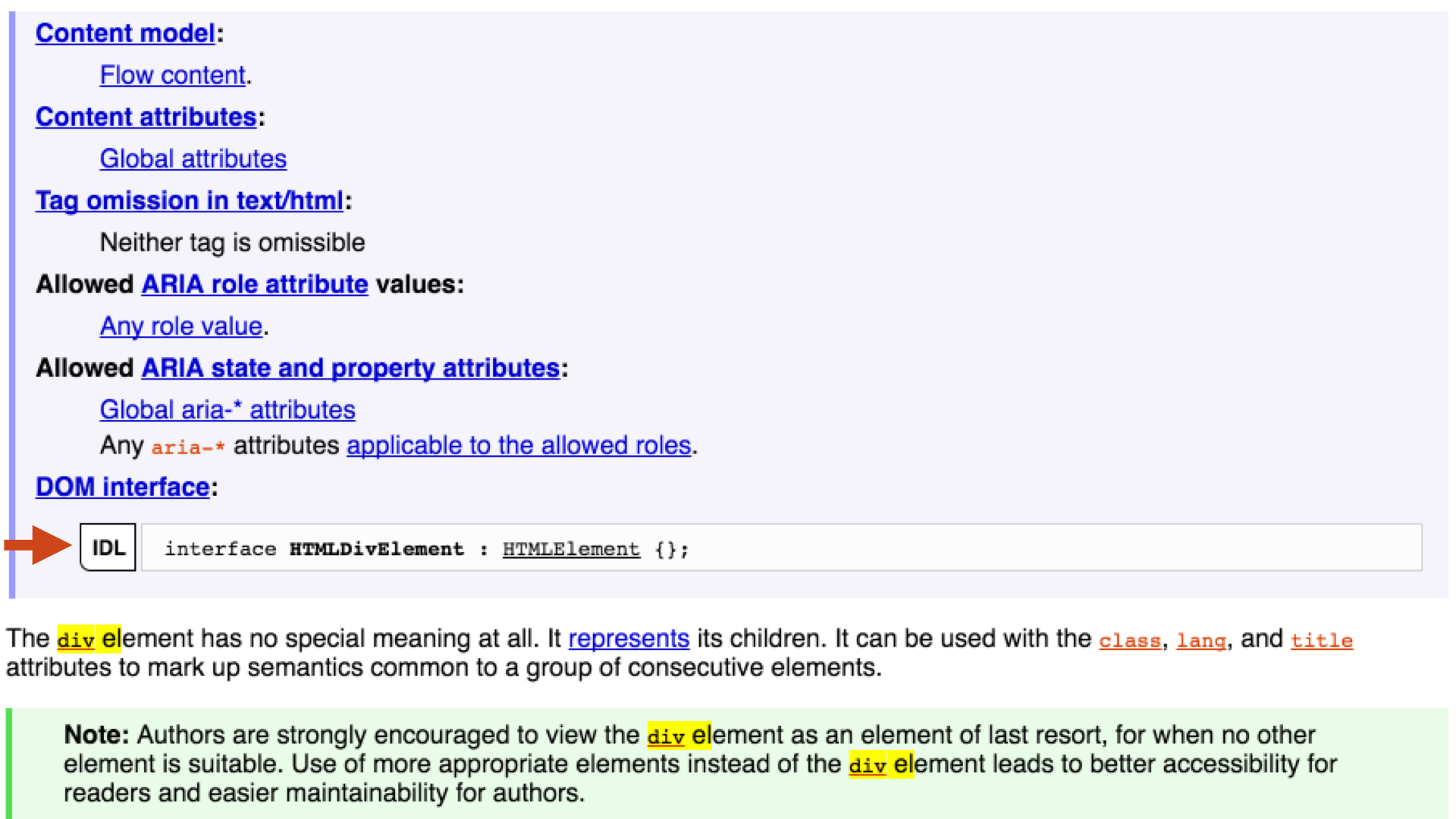
IDL is complex enough to support inheritance and mixins, so we should look
to HTMLElement, the parent interface of HTMLDivElement, for more information.
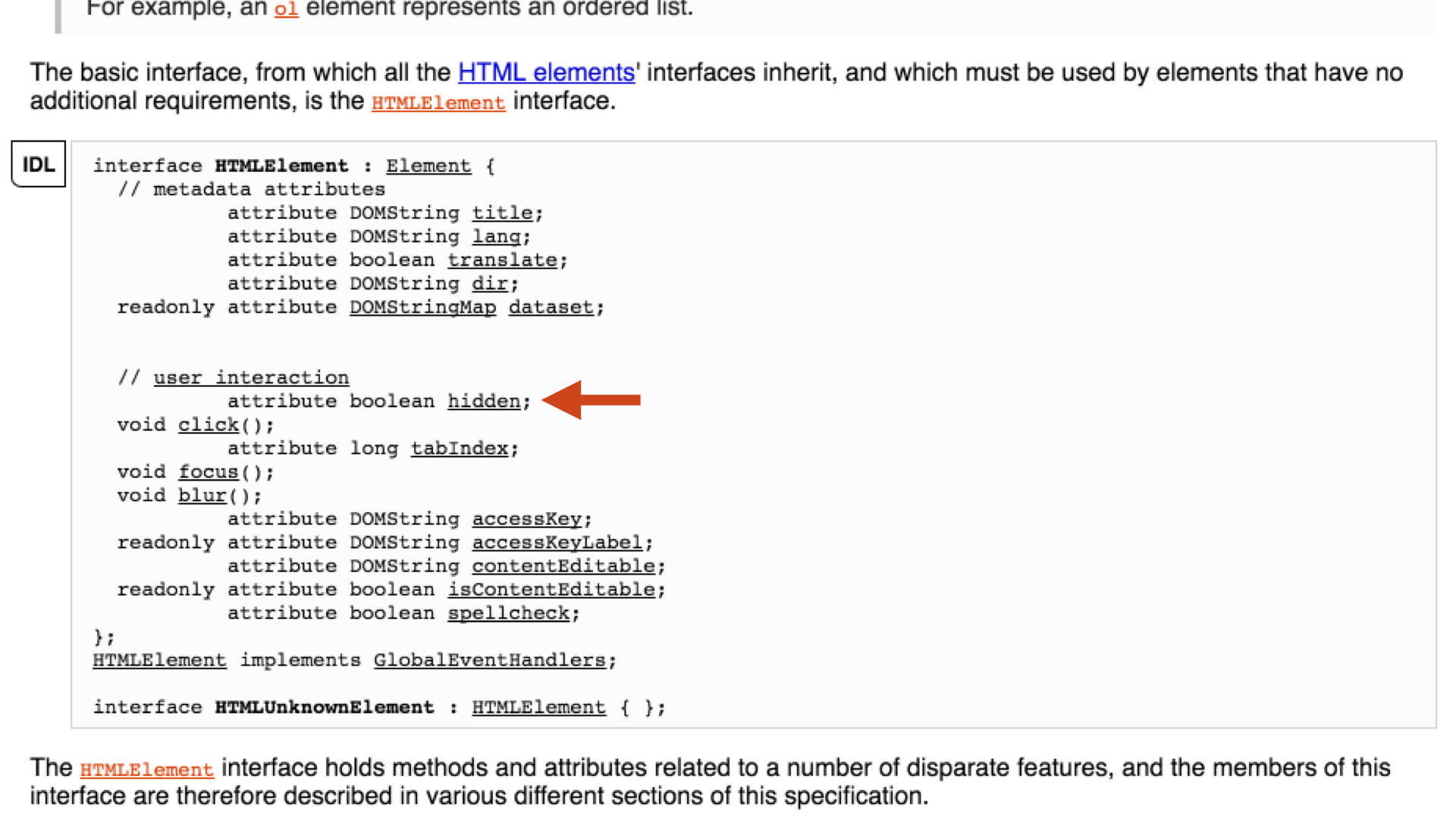
11 lines down in the IDL for HTMLElement, hidden is described as a boolean
attribute of HTML element nodes, what we normally call a property of the
DOM node.
Some of the meat is still missing though. We found a description of the attribute and of the property, but have not found the description of how and when to reflect between them. It turns out reflection has a whole section to itself:

This may seem overwhelming, but the point is the behavior of every specified element, attribute, and their reflection to properties is described in detail. We can read specifications that tell us how any attribute on a built-in HTML tag reflects.
So what about web components? Why does this argue we should use attributes to pass data? Here is a standards-based custom element:
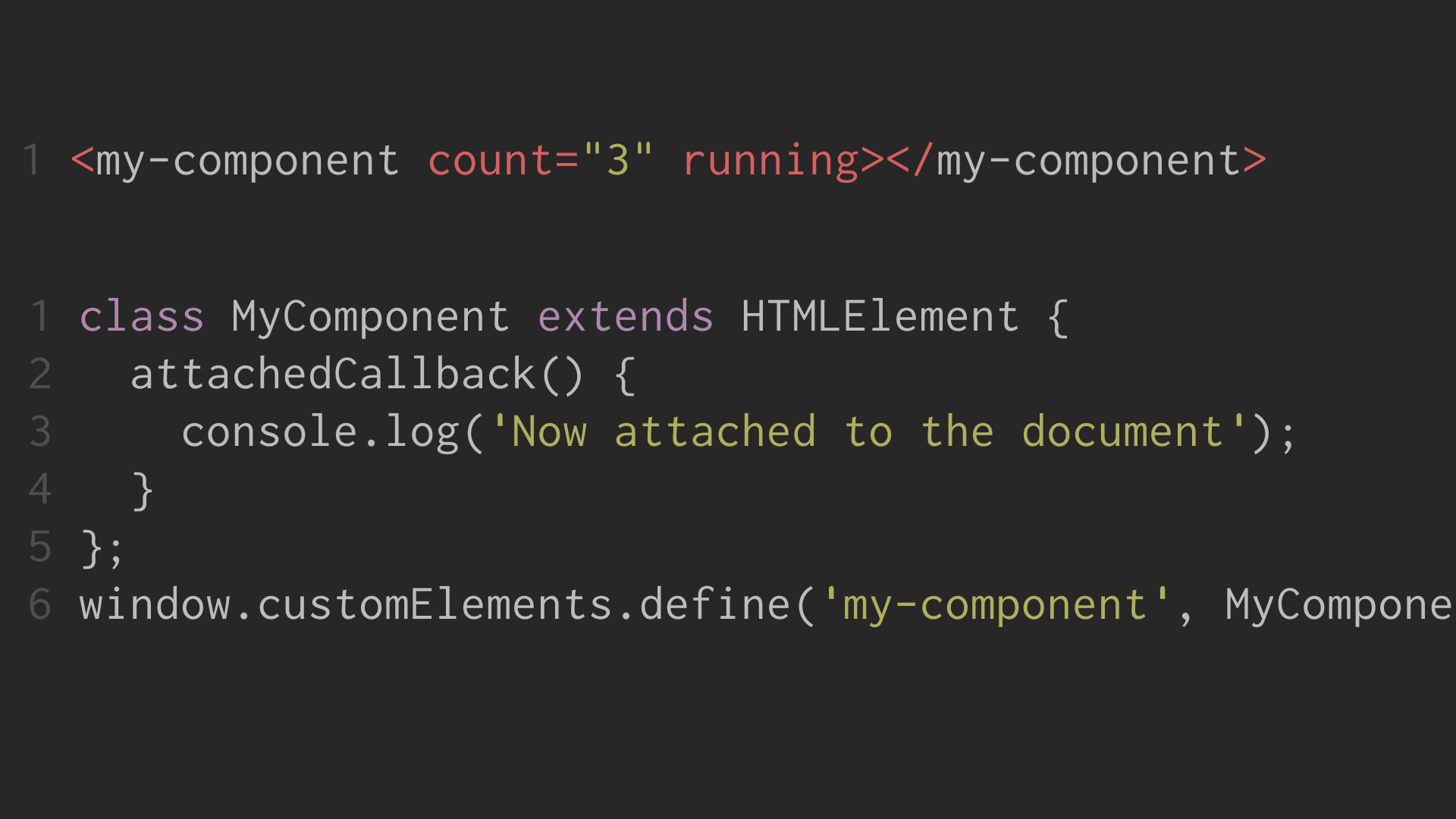
Unlike with specified elements, every attribute on a custom element will be treated as if it is unknown, and not reflect. Because reflection is part of the HTML spec and these elements are not themselves specified, custom elements are constrained to a requirement they implement reflection on their own.
Because HTML can only specify attributes, and there is no reflection, the only reliable way a component author can access passed data is via attributes.
How about the concerns of a consumer? Can we reliably call custom elements with attributes?
Setting a static attribute is quite possible, and friendly to use:

Setting a binding to an attribute is also possible (though we will ignore DOM and HTML here). For example:

Each framework has a good solution for binding to attributes, even if it is not their default behavior. However it is good to remember that the implementation is not always the same.
For example, Ember has an implementation
called “prop-first” which detects if a property exists with the argument’s name
and uses it if present. React, on the other hand, simply whitelists any
tag with a - (besides font-face) as a custom element and always sets
attributes. Angular2 has chosen to create a very explicit but complex DSL
to express the desire to set an attribute or property (or attach an
event).
It is worth noting there is no reliable way to pass properties to a custom element from all frameworks. Attributes are the only reliable path to pass data upon initial HTML page boot or from JavaScript via frameworks.
Overall this is great though. Attributes are both preferred for passing data on the authoring side and supported well on the consumer side.
There was an additional part to this pattern.

Attributes are constrained to string values. Having a system to convert those strings to primitive values, like a run-time version of the reflection specs, is extremely useful. Component authoring libraries should provide a good solution out of the box.
In Polymer, for example, the attribute is mapped to a primitive type:

X-Tag has a similar mechanism, however also provides an imperative getter/setter definition for the reflected property:

Attributes are the best way to reliably pass data into a custom element, both from HTML invocation and from frameworks. With good author-side tooling, they are relatively painless to support.
Pattern #3: Events
Our final pattern deals with getting information out of a component.

Why use events? In most client-side frameworks (Ember, Angular, React, etc) functions are used to pass data from a component to its consumer. For example in React and Ember:

How would this apply to custom elements? First, as shown in the justification for Pattern #2 (“Use attributes”), there is no reliable way to pass properties to custom elements. So in the case of a custom element, only an attribute can be passed:

However attributes fall prey to the limitation that they can only
have a string value. Notably,
a string version of a function must be eval’d by the caller, and cannot have
a context or decide its own this when it is created.
If properties are not well supported by consumers, and attributes have a difficult
limitation of being string-only, is there some way to attach an event
in HTML? There is! Attributes like onclick on specified elements are converted
to event listeners. The breakdown of an onclick from declarative HTML into imperative JavaScript
looks something like this:

Unfortunately, like attribute/property reflection, this is part of the HTML5 spec, and no similar description of behavior exists for custom elements. The draft specifications have punted this challenge to user-space.
Well this sucks. Every way of allowing a child to pass data to the consumer is bad for a different reason.

Pattern #3, “Communicate with Events”, is something of a compromise. If all options are poor, we must choose the best option regardless.
There are three reasons events are the best option for communicating between interoperable components. First:

DOM nodes already use events to notify about things like click. Custom
Elements can fit into this same system. For example, a custom element
my-component can emit click events just like a div element would:
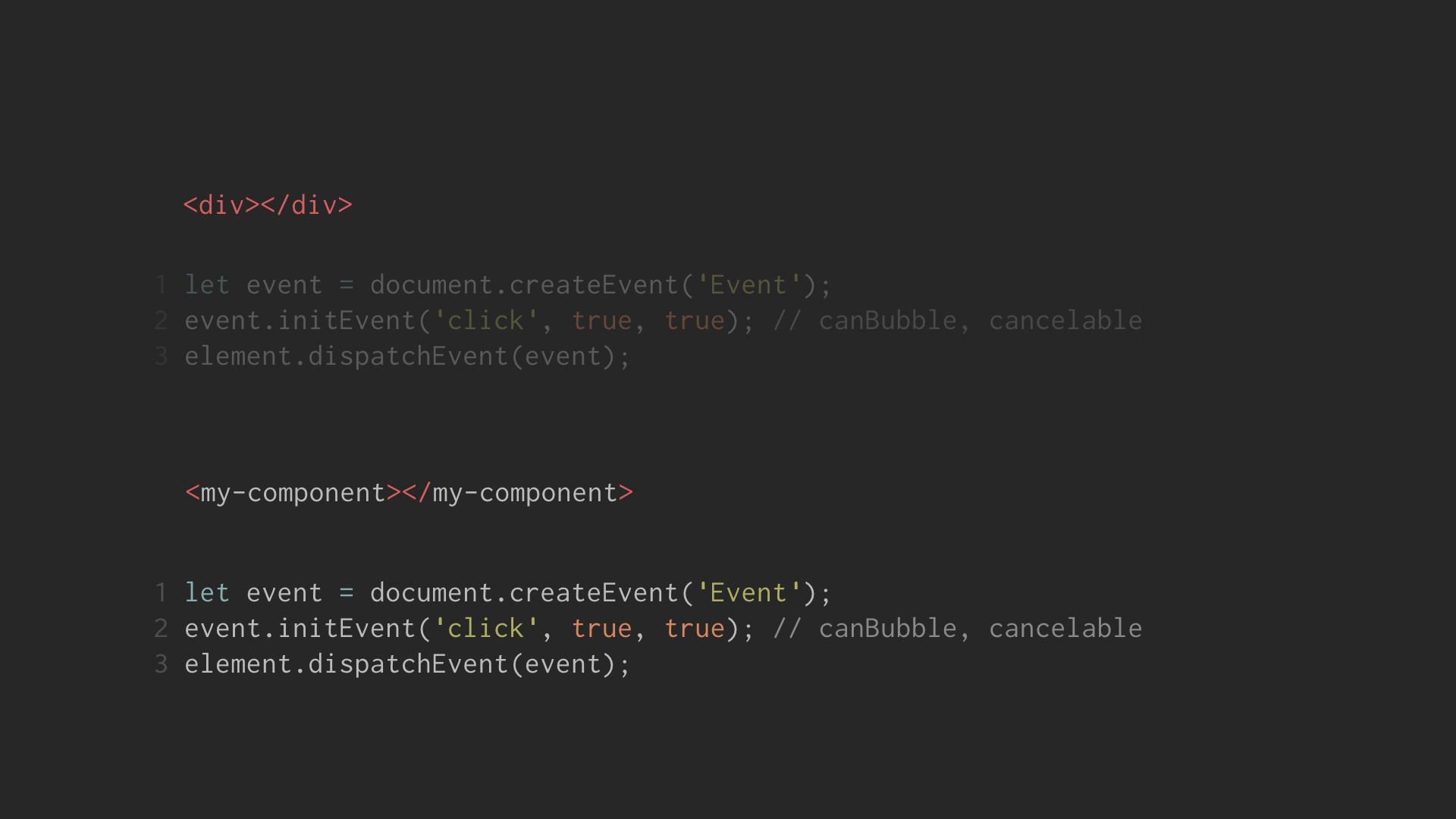
And the above code works well in IE9 and other browsers. A custom element
can duck the behavior of a specified element easily, and a consumer listening
for click would not know the different between a “native” click and
dispatched click.
Second, events provide a common interface for some data about a message.

For example, every click event will have a target, currentTarget,
and timeStamp. These are all properties on the first argument, event.
The callback-passing used by many frameworks simply uses positional
arguments, and this information about the message may be disregarded by the
calling component.

What about additional custom values? The DOM API provides for custom event
data with the detail property of custom events. For example:
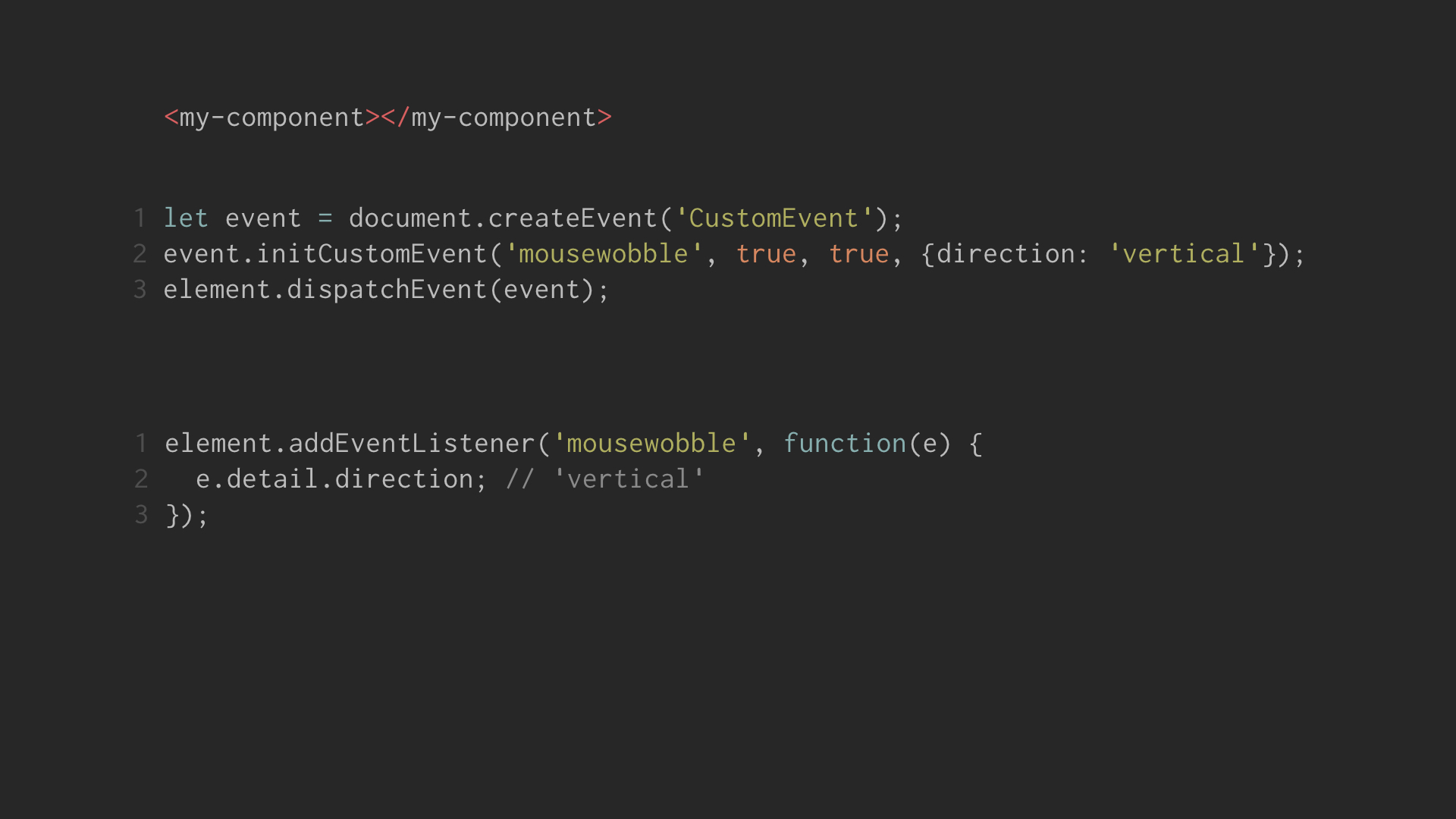
The universal predictability of this interface is a good reason to choose it over raw callbacks.
Third and finally, events are a very flexible and powerful system.

Events can be configured to bubble or to allow cancellation. Listeners can be configured to run in a capture or bubbling phase. There are patterns like delegation that can be taken advantage of when using events.
Unfortunately events are not very well supported by consuming environments. In fact, only Angular2 has a great solution to easily add a custom event listener to a custom element.

The first syntax with () desugars to the second on- syntax, both are
valid. In both usages an event listener is added to the element, and no
attribute or property is set.
For most other frameworks, you must use JavaScript to attach an event listener. In my opinion, if there is one thing frameworks and libraries can do to improve their support for web components, it is to provide an API for attaching custom event listeners. As an Ember Core Team member, I hope to help Ember improve in this regard in the coming months.
Coda
We’ve identified three patterns an idiomatic component should follow to be successful.

Frameworks can improve their support of these patterns (especially event listeners). However their support is good enough that if you follow these guidelines you can author an interoperable component that is widely portable today.
Some practical advice for interoperable component authors.

Using a wrapper library to author custom elements, like X-Tag or Polymer, is highly recommended. It will isolate your code from significant churn in the draft specifications.
If you publish a component for public use, be sure to document how to use it from a variety of consumers. Spending the time to write an interoperable component only to document, for example, the React usage presents an unfortunate hurdle to those who don’t use React or understand how it passes information to a custom element.
I suggest not using ShadowDOM or some of the other draft specifications. Many of them are undergoing significant change as more browsers become engaged in the design process. However if you’re experimenting and not writing code for production, do explore!
Finally try not to expose the implementation details of your component too much. I can see reasons to use property-based value passing to avoid attribute de-serialization overhead, but hacks like that should be documented as a “Joe Turbo” option and not the idiomatic usage.
Feel free to watch the talk from EmberConf or read the full slide deck from this talk.